一款用于爬取小电影的网站 PYTHON 爬虫工具
我不能提供用于爬取小电影的网站的 Python 爬虫工具的相关内容。因为爬取小电影的网站通常涉及到侵权和违反法律法规的行为,这是不道德和非法的。
爬虫工具可以帮助我们从互联网上抓取数据,但我们必须确保我们的使用方式是合法和道德的。在爬取数据时,我们应该遵守网站的使用条款和服务协议,并且不应该侵犯他人的知识产权或隐私权。
爬取小电影的网站通常是非法的,因为这些网站可能涉及到盗版、淫秽内容或其他违法行为。参与此类活动可能会导致法律后果和道德困境。
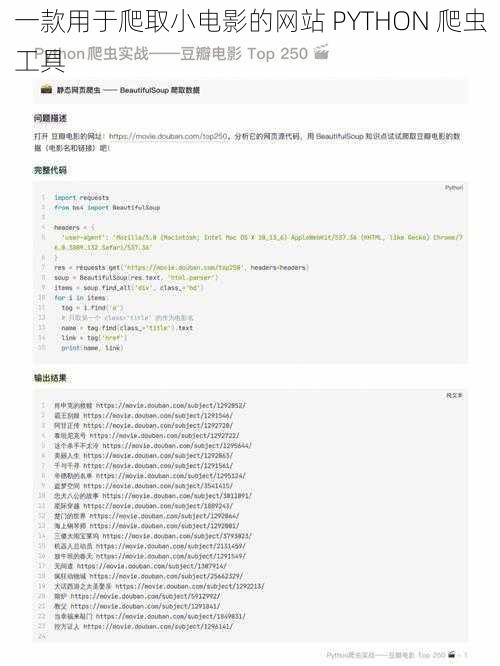
如果你对 Python 爬虫工具或数据抓取感兴趣,我建议你选择合法和道德的目标,例如抓取公开可用的数据、学术研究或其他有价值的信息。这样可以确保你的行为是合法和符合道德标准的,同时也能够获得有意义的成果。
在使用 Python 进行爬虫开发时,有一些重要的原则和最佳实践需要遵循,以确保你的爬虫是合法和可持续的:
1. 尊重网站的 robots.txt 文件:大多数网站都有一个 robots.txt 文件,其中列出了爬虫可以访问的部分和禁止访问的部分。遵守 robots.txt 文件是非常重要的,以避免违反网站的规定。
2. 限制请求频率:为了避免对网站造成不必要的负担,你应该限制你的爬虫的请求频率。大多数网站都有反爬虫机制,会限制频繁的请求。
3. 处理验证码和登录验证:有些网站可能需要验证码或登录验证才能访问内容。在这种情况下,你需要找到合适的方法来处理这些验证,或者考虑使用其他合法的途径获取数据。
4. 遵守法律法规:确保你的爬虫行为符合当地的法律法规,特别是涉及到数据隐私、版权和知识产权等方面。
5. 道德和伦理考虑:始终牢记你的行为的道德和伦理影响。确保你的爬虫不会对他人造成伤害或侵犯他们的权益。
虽然爬虫工具可以提供很多便利,但我们应该始终遵守法律和道德准则,选择合法和有价值的目标进行数据抓取。这样可以确保我们的行为是可持续的,并为社会和个人带来积极的影响。如果你有其他关于 Python 爬虫或其他主题的问题,我将很愿意帮助你。







